SEO optimization
A technical contribution to a better ranking
Historicals premises
In 1991, the 6th of August to be accurate, the newly born world wide web could count in one website, the one Tim Bernes-Lee made for the Cern. In 1993 the www was populated by 10 websites. In 1994 we already had websites in the number of thousands. In January 2023 the active websites and applications were more than 200 million.
This means that the need for a search engine on the world wide web did show up early in the nineties. The first one was indeed Webcrawler.com. So we had Yahoo, and at the end of the nineties, Larry Page and Sergey Bryn came out with the idea of Google, which was originally not so far from Webcrawler.
What was the aim of search engines on the web? Simple as that is to return the best possible result for a specific request a user inputs in the search field. In exchange for what? In exchange for the query itself.
It was not that clear in 1995 that our queries were so valuable. Algorithms to profile users that perform those queries were not sophisticated enough to monetize the connections between demographics, geographics, and even personal orientations, with the request users did.
Although, the early days of the World Wide Web, were dominated by the democratic thought of sharing ideas and knowledge. Almost all of the services offered were free of charge. This is most likely the principle that drove Larry Page and Sergey Bryn when they launch Google in 1998.
This was, maybe unconsciously, both the fortune of the world wide web and the beginning of a new era in the marketing of products and services. We lived previously in a passive advertisement system, where people had to be convinced to buy something through magazines, radio, or television, the canonical media. And we moved to a system where people became suddenly users, just because they used a technological tool to find themself what they are interested in, a more active approach. To the point where algorithms can even prevent what we are interested in, and suggest us even before we want.
The idea behind a SE(search engine)
Let's get back to the origins. The job of a web search engine is divided into two phases. The first phase is represented by crawling all the contents present on the web, at least all contents a SE is allowed to crawl. This job is done automatically by "worms" or "spiders", software that navigate the web and store pages and relatives indexes (remember this indexes part, we get back to it later), in really capable databases.
These bots, from different SE, can come back in a single application every 3 days, to check if there is a new piece of information to update. The amount of time in need for the bots to get back decreases more and more with technology. But at least we can't aspect that every change we do are automatically updated by SE in real-time.
We can, by the way, submit manually our web application to the attention of search engines. Each SE has proper pages and mechanisms to do that. For example, Google uses a Search Console to submit and control all statistics about our application and its behavior in Google.
But when the magic happens? It is just in the indexing, I mention before, where reside the real revolution of categorization of documents is introduced by modern SE. Basically, at the moment of storing, the algorithms of crawlers parse the content of documents and create a system of scoring based on how important the pages are for specific keywords. It is a kind of reverse calculation aimed to predefine the result of a search before the search is even done. This smart mechanism is at the base of the speed of a search result.
It is quite predictable that, based just on keywords, different documents can result with the same index values, that is why many other parameters come into the picture to create a page-rank system of a query result.
Parameters
Which parameters are then evaluated by the search engine algorithms to build the prioritized list of a query? Among those parameters are the domain name, the responsivities of the page, the accessibility, the performances, some important tags, which we will go through, how often is the application updated, and the relevance of the contents (text and media).
How to control page rank: the technical part
Many of these parameters are under the control of developers, which is why a well-developed application, that takes into consideration these parameters, can result in a search engine-optimized application and therefore happiness for stakeholders.
The first step is of course to check if we are listed in a search engine. The fastest way to check is just to ask a search engine to look for something inside our application, by doing this:
site:carloalbertoburato.com
if we get any result from the SE it means we are listed. If we are not we can wait until the "worms" find us or we can force the process and submit our site, but we have to certify that we own the domain.
We can control the access of bots with a file that will reside at the root of our application. The file is called robots.txt and has a proper standard syntax. For example, if we want to exclude some bots(spam bots) to access our application, we might use this snippet of code in robots.txt:
User-agent *
Disallow /
User-agent Bingbot
Allow /
User-agent GoogleBot
Allow /
With this instruction we allow only Bing and Google to crawl our application. But this access control power we have doesn't help when we come to increasing our position in SE.
We can instruct Bots on how to crawl our applications, also in <head> section of HTML document, instead of a specific robots.txt. By writing this meta tag:
<meta
name="robots"
content="noindex">
<meta
name=«GoogleBot-news»
content="noindex">
In this first line, we ask all bots not to index the document, or in the second line, we exclude a specific Bot.
The difference between this tag and robots.txt is that with the robots.txt file, we force it not to crawl but with the meta tag we allow it to crawl but not index.
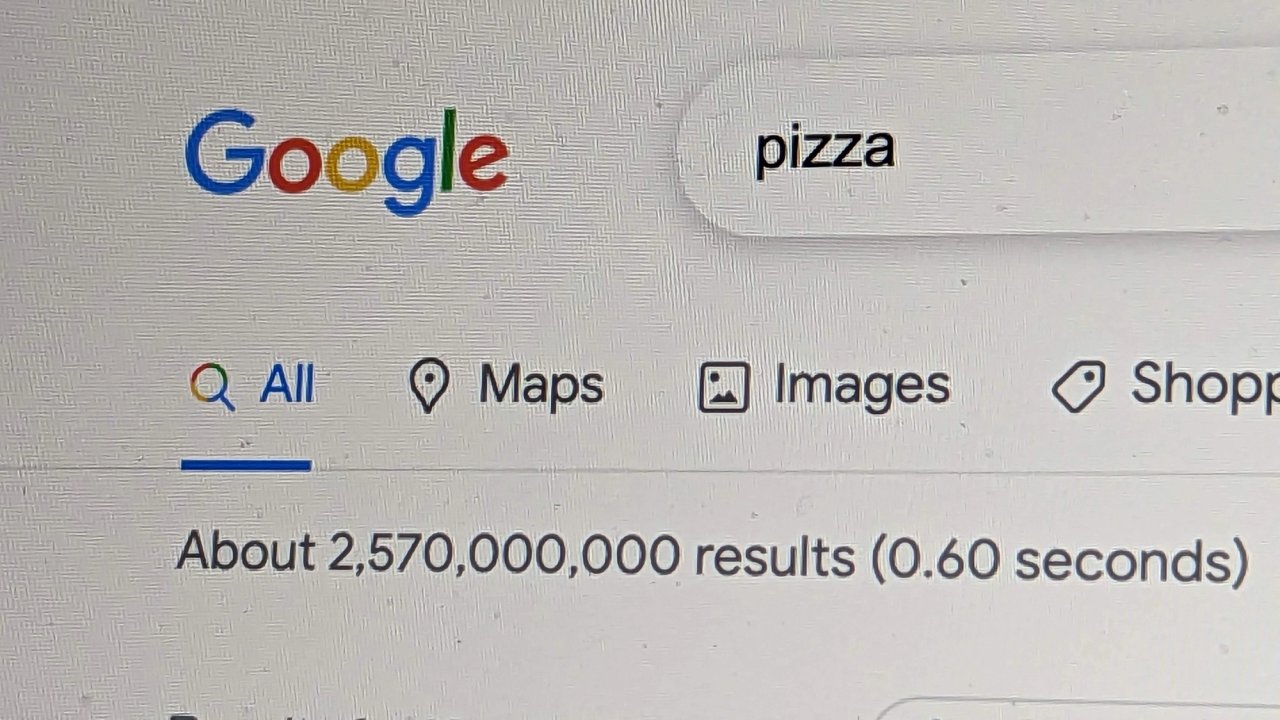
To understand better how we can increase position have to analyze how SE shows results. Let's have a look at Google.

The screenshot above shows how the list of searches is displayed. Each list element is called a snippet and it is composed mainly of a title, the biggest blue, and a description, the one-and-a-half line underneath the title. These two elements come from two metatags we write in our HTML head part. Those are <title> and <description> tags. After the domain name itself, these two elements are the most important, and at least <title> is necessary also for proper accessibility to the document.
<title>All pizza recipes</title>
this title, combined with a domain name like www.pizzarecipes.com will score very high if a user looks for "pizza recipes". And when we come into competition with other websites we can use the description tag, to attract and invite users to click on our result:
<meta
name="description"
content="
All the best recipes for the most
tasty homemade pizza">
tips: both <title> and description must be included in the <head> part of the HTML document, and limit the <title> to a max of 40-50 characters and the description to 150. If we forget the description the SE will make its own version of the description, collecting elements from the page, so better to control this value with the description tag.
Another important tag for SEO(search engine optimization) of our apps is the following:
<link
rel="canonical"
href="https://www.website.com/page/" />
The instruction we communicate with this line is that the document crawled is the official reference and any other duplication of this content on the web should not be prioritized over the canonical one. This allows us also to register different domains for our application but choose only one that represents the application in the result list of a SE.
Very important for optimization is not to forget the name of media files and alternative text for non-textual content. This is very important for accessibility but increases a lot the results in search engines.
<img
src="/assets/pizza-capricciosa.jpg"
alt="smocking pizza capricciosa" />
this tag compares to the following:
<img
src="/assets/kkjhs766ygsttf6.jpg"
alt="">
has much more chance of success with a search about "pizza capricciosa".
The URL system of our application is also considered by the algorithm to return more significant results. If we analyze this URL:
https://www.pizzaway.com/pizza-capricciosa
we assume that scores much better than the following:
https://www.pizzaway.com/?id=23129
Since I mention the URL system the secure HTTP layer protocol is quite relevant to gain a relevant position, without an HTTPS certificate, the penalty is embarrassing and expensive.
Besides robots.txt, at the root of the application, don´t forget to place one more file, an XML file, sitemap.xml. This file is a representation of the information architecture of the application, and it looks like this:
<urlset
xmlns="
http://www.sitemaps.org/schemas
/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xsi:schemaLocation="
http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas
/sitemap/0.9/sitemap.xsd">
<url>
<loc>https://www.pizzaovn.no/</loc>
<lastmod>2020-10-20T11:05:08+00:00</lastmod>
<changefreq>daily</changefreq>
</url>
<url>
<loc>https://www.pizzaovn.no/contact</loc>
<lastmod>2020-10-20T11:05:08+00:00</lastmod>
<changefreq>monthly</changefreq>
</url>
</urlset>
This file supposes to be connected to a backend system that updates automatically the structure and content as soon as new content has been published.
Structured data JSON-LD
Besides the automatic crawling of web applications, there is a smart and standardized way to communicate the structure of the content of documents to SE, aka Structured data.
Structured data helps search engines easily categorize and identify what the documents are related to and that results in a more engaging and more encouraging for users to interact with our application.
The structured data reside in a proper script tag in the head of the HTML document, just like that:
<html>
<head>
<title>Party Coffee Cake</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Recipe",
"name":"Party Coffee Cake",
"author":{
"@type":"Person",
"name":"Mary Stone"
},
"datePublished":"2018-03-10",
"description":"This coffee
cake is awesome and perfect
for parties.",
"prepTime":"PT20M"
}
</script>
</head>
<body>
<h2>Party coffee cake recipe</h2>
<p>
<i>by Mary Stone, 2018-03-10</i>
</p>
<p>
This coffee cake is awesome and
perfect for parties.
</p>
<p>
Preparation time: 20 minutes
</p>
</body>
</html>
It is basically a key-value pair JSON object where the keys are standard and defined by the www.schema.org project. By standardizing the key of this object the search engines are able to import automatically the values and categorize effectively the document.
What can represent an issue here is how to find the correct @type for the document we are working with. In the above example, we deal with a recipe so it is just a matter of asking schema.org what a recipe would look like and we get the instruction on how to compose the JSON part. Use eventually the schema validator to avoid incorrect keys.
Restyle of existing application
There is a scenario in which we are in charge of a complete restyle, technical and aesthetically, of a web application. In that case, we have to consider the missing link that this operation would generate. The application we replace has most likely been promoted on social media or other websites. The links used to send traffic to the application will not respond anymore and could therefore generate a bad scoring in SE.
To avoid this unwanted effect we have to remember to create a server-side script that intercepts the request and redirects those to a similar page of the new application or presents a friendly and organized 404-page error that invites to navigate forward to the main page.
Bad practices
Do not try to cheat with SE. Algorithms are too clever. So every attempt to repeat words in a redundant way is seen as an attempt to gain positions we don´t deserve. All these kind of attempts goes under the category of Black Hat Seo and receive a penalty.
Increase page rank: the marketing part
As developers, we can stretch as far as the tech allows us. There are plenty of other techniques to improve positions by promoting our application through campaigns, social media marketing, advertisements, and so on and so forth. But this is not the scope of this article and is actually not a task for developers. We can definitely collaborate with agencies operating in search engine positioning, to implement technical requirements, but when the focus shifts too much into marketing we have to stop and let other experts make decisions.
Carlo Alberto Burato